
Jillur Quddus • 1 September 2020
Back to Course Overview
Introduction
In this module we will introduce additional common collection data structures available in Python and associated methods, including:
- Tuples - constructing, accessing and manipulating tuple data collection structures
- Dictionaries - constructing, accessing and manipulating dictionary data collection structures
The source code for this module may be found in the public GitHub repository for this course. Where code snippets are provided in this module, you are strongly encouraged to type and execute these Python statements in your own Jupyter notebook instance.
1. Tuples
In Python there are four common built-in data structures that are designed to hold collections of data in such a way that enables quick and efficient operations on that data, such as insertion, deletion and retrieval operations. In the module Control and Evaluations Part 2 we introduced list data structures, and in the module Data Aggregates Part 1 we explored advanced operations involving lists.
In this subsection, we will focus on another common collection data structure, namely tuples. A tuple in Python is an immutable (cannot be changed) collection of ordered elements, where duplicate elements are allowed. Each element in a tuple is an object in its own right, whether a basic literal or more complicated object.
Note that lists, tuples and strings are examples of sequence data types in Python - that is a collection of elements supporting efficient element access. A list is an example of a mutable sequence whilst tuples and strings are examples of immutable sequences. Common Python standard library functions such as
len(),max()andmin()can be applied to sequence data types, which explains why they work for lists, tuples and strings alike. And sequences themselves are a type of iterable in Python - that is an object whose elements can be iterated over.
1.1. Defining a Tuple
A tuple is created by using round brackets (). Tuples may be instantiated with its contents or as an empty tuple. Note that in order to create a tuple containing only one element, we define the first element followed by a trailing comma. If we forget to include the trailing comma, then Python will recognise the object as a string instead of a tuple, as follows:
In the example below, we use the Python
type()function to return the type of any given object.
# Create an empty tuple
empty_tuple = ()
print(empty_tuple)
# Create a tuple with only 1 element by using a trailing comma
tuple_one_element_1 = 'elem1',
print(tuple_one_element_1)
tuple_one_element_2 = 10,
print(tuple_one_element_2)
tuple_one_element_3 = ('a', )
print(tuple_one_element_3)
# If we forget the trailing comma, then Python will recognise it as a string
print(type(tuple_one_element_1))
tuple_one_element_4 = ('a')
print(type(tuple_one_element_4))
# Create a tuple with 5 elements
my_tuple = (1, 2, 3, 4, 5)
print(my_tuple)
Tuples can also be initialised given another iterable, such as a list, using the tuple() constructor function as follows:
# Initialise a tuple with a list
my_tuple_from_a_list = tuple(["a", "b", "c"])
my_tuple_from_a_list
1.2. Standard for Heterogeneity
A standard in Python is to use lists to store homogeneous elements (that is elements of the same type) and to use tuples to store both homogeneous and heterogeneous elements (that is elements of different types) within the same collection data structure. In the following example, we create a tuple to store information regarding a person including their first name, last name and age.
# Create a heterogeneous tuple containing information about an individual
individual_tuple = ("Barack", "Obama", 59)
print(individual_tuple)
1.3. Tuple Use Cases
At first glance the need for tuples may seem non-existent bearing in mind that Python provides us with the list data structure. However tuples are useful in many situations, including but not limited to:
- Loading data that should not be changed by our Python application, such as a read-only record from a database or flat-file
- Storing related data that represents a single entity or compund value. For example, you may store heterogeneous data regarding an individual in a single tuple such as ("Barack", "Obama", 59)
- Iterating through a constant set of values
- Multiple assignment in a single statement via tuple packing and sequence unpacking techniques - see 1.10. Tuple Assignment below
1.4. Index and Negative Indexing
Since a tuple is a sequence data type, its elements can be accessed using index numbers (positive or negative) inside square brackets just like lists and strings, as follows:
# Access elements in a tuple by their index numbers
my_tuple = ("Barack", "Obama", "04/08/1961", 59, "Male", 1.85, "American")
print(my_tuple[0])
print(my_tuple[3])
print(my_tuple[-1])
print(my_tuple[-2])
1.5. Slice Notation
Similarly, again since a tuple is a sequence data type, slicing notation can be used to access a specific subset of elements in a tuple, as follows:
# Use slice notation on tuples
print(my_tuple[:])
print(my_tuple[2:])
print(my_tuple[:4])
print(my_tuple[2:5])
print(my_tuple[1::2])
1.6. Tuple Length
Like strings and lists, we can use the len() function to identify the number of elements in a given tuple, as follows:
# Using the len() function on tuples
print(len(my_tuple))
1.7. Tuple Membership
The membership in operator, as discussed in Control and Evaluations Part 1, allows us to test whether a given element can be found within a given tuple (or another type of collection).
# Test whether an element exists in a tuple
if 'Obama' in my_tuple:
print(f"This tuple correponds to information about Barack Obama")
else:
print(f"This tuple does not correspond to information about Barack Obama")
1.8. Deleting Tuples
Since tuples are immutable sequences, we cannot delete specific elements from a tuple. However we can use the del keyword to delete an entire tuple from memory, as follows:
# Delete a tuple
print(my_tuple_from_a_list)
del my_tuple_from_a_list
print(my_tuple_from_a_list)
1.9. Joining Tuples
We can use the + operator to join one tuple to another tuple, which will create a new tuple as follows:
# Join two tuples to create a new tuple
my_first_tuple = ('a', 1, 'b', 2, 'c', 3)
my_second_tuple = ('d', 4, 'e', 5, 'f', 6)
my_third_tuple = my_first_tuple + my_second_tuple
print(my_third_tuple)
1.10. Tuple Assignment
An elegant application of tuples is the simultaneous assignment of variables in one Python statement via tuple packing and sequence unpacking. Tuple packing enables mutiple values to be packed together into a tuple, as follows:
# Use tuple packing to pack values into a single tuple
barack_obama = "Barack", "Obama", 59
print(barack_obama)
print(type(barack_obama))
Coversely, sequence unpacking enables multiple variables to be assigned the values of the elements in a given sequence (in this case a tuple), as follows:
Note that sequence unpacking requires that there are as many variables on the left side of the assignment operator as there are elements in the given sequence.
# Use sequence unpacking to assign values to variables from a given sequence
barack_obama_first_name, barack_obama_last_name, barack_obama_age = barack_obama
print(barack_obama_first_name)
print(barack_obama_last_name)
print(barack_obama_age)
We can also use tuple assignment to efficiently swap the values assigned to two different variables, as follows:
# Swap values assigned to two different variables
a = 10
b = 99
print(a)
print(b)
(a, b) = (b, a)
print(a)
print(b)
1.11. Tuple Methods
The Python standard library provides two in-built methods that can be applied to tuples, as follows:
tuple.count(x)- returns the number of occurences of a given valuexin a tuple.tuple.index(x)- returns the index number where the first occurence of a given valuexis found in the tuple. If it is not found in the tuple, then then method will raise an exception.
# Create a tuple
my_tuple = (0, 1, 0, 1, 1, 0, 0, 1, 1, 1)
# tuple.count(x)
print(my_tuple.count(0))
print(my_tuple.count(1))
print(my_tuple.count(2))
# tuple.index(x)
print(my_tuple.index(0))
print(my_tuple.index(1))
print(my_tuple.index(2))
1.12. Iterating Tuples
Similar to lists, both for and while loops can be applied to iterate over tuples (though in most cases it is more efficient to use a for loop), as follows:
# Create a tuple
my_diatomic_tuple = (0, 1, 1, 2, 1, 3, 2, 3, 1, 4, 3, 5, 2, 5, 3, 4)
# Iterate the tuple using a while loop
i = 0
while i < len(my_diatomic_tuple):
print(f'Diatomic Sequence - Element #{i + 1}: {my_diatomic_tuple[i]}')
i += 1
# Iterate the tuple using a for loop with the range function
for x in range(len(my_diatomic_tuple)):
print(f'Diatomic Sequence - Element #{x + 1}: {my_diatomic_tuple[x]}')
# Iterate the tuple using a for loop with the in operator
for elem in my_diatomic_tuple:
print(elem)
# Iterate the tuple using a for loop with the in operator and enumerate function
for idx, elem in enumerate(my_diatomic_tuple):
print(f'Diatomic Sequence - Element #{idx + 1}: {elem}')
1.13. Tuples as Return Values
We will explore functions in further detail in the Functions and Modules Part 1 module of this course. However at a high-level, functions are blocks of code designed to undertake a specific task. A function may expect zero or more parameters or arguments to be passed to it by the code calling the function. And a function may return zero or more values.
In order for a function to return more than one value, we can return a tuple of elements. The following example defines a Python function that will return both the circumference and area of a circle given its radius:
import math
# Return both the circumference and area of a circle given a radius
def circle(radius):
""" Return the (circumference, area) of a circle given its radius """
circumference = 2 * math.pi * radius
area = math.pi * radius * radius
return (circumference, area)
my_radius = 10
my_cirumference, my_area = circle(my_radius)
print(f'The circumference of a circle of radius {my_radius}cm is {my_cirumference}cm')
print(f'The area of a circle of radius {my_radius}cm is {my_area}cm\u00b2')
1.14. Tuples in Lists
As defined in the Control and Evaluations Part 2 module of this course, a list in Python is an ordered and mutable (changeable) collection where duplicate elements (members/items) are allowed. Each element in a list is an object in its own right, whether a basic literal or more complicated object. As such, an element in a list can even be a tuple - this is useful, for example, when you have multiple groups of constant values that you wish to store in a list, as follows:
# Create a list of tuples
my_list_of_tuples = [(1, 'abc'), (2, 'def'), (3, 'ghi')]
print(my_list_of_tuples)
print(my_list_of_tuples[0])
print(my_list_of_tuples[0][0])
print(my_list_of_tuples[1])
print(my_list_of_tuples[1][1])
print(my_list_of_tuples[2])
print(my_list_of_tuples[2][0])
print(type(my_list_of_tuples))
1.15. Lists in Tuples
Similarly, each element in a tuple is an object in its own right, whether a basic literal or more complicated object. As such, an element in a tuple can even be a list, as follows:
# Create a tuple of lists
my_tuple_of_lists = ([1, 2, 3], ['abc', 'def', 'ghi'])
print(my_tuple_of_lists)
print(my_tuple_of_lists[0])
print(my_tuple_of_lists[0][0])
print(my_tuple_of_lists[1])
print(my_tuple_of_lists[1][1])
print(type(my_tuple_of_lists))
1.16. Multi-Dimensional Tuples
As discussed in the Data Aggregates Part 1 module of this course, a matrix can be represented as nested lists within lists, sometimes referred to as n-dimensional or multi-dimensional arrays. In order to create an immutable matrix that cannot be changed once it has been initialised, we can define nested tuples within tuples. An example use case of an immutable matrix is when creating an Identity Matrix in linear algebra for the purpose of matrix multiplication, as follows:
# Create an immutable 3 x 3 identity matrix
identity_matrix = ((1, 0, 0), (0, 1, 0), (0, 0, 1))
for row in identity_matrix:
for elem in row:
print(elem, end=' ')
print()
1.17. Summary
As we have seen, tuples are similar to lists in many ways. However there are some core differences; tuples are immutable and usually contain a heterogeneous collection of elements that together represent a single entity or compound value. The elements in a tuple can be accessed via either indexing, iteration or sequence unpacking. However lists are mutable and usually contain a homogeneous collection of elements. The elements in a list can be accessed via either indexing or iteration.
2. Dictionaries
Dictionaries in Python (also known as associative arrays in other programming languages) are a mutable collection of key:value pairs, that is a key object mapped to a variable object. Dictionaries are optimised for the quick lookup of a value by its key and as such are an optimal data structure for a wide range of use cases, including storing lookups for ETL (Extract-Transform-Load) data pipelines, word frequencies (where the keys are words, and the values are their frequencies in a given document), natural language dictionaries (where the keys are words, and the values are their definitions), and search engines (where the keys are search terms, and the values are URLs pointing to web resources containing those search terms). The following table provides an example dictionary, where the keys are countries and the values are the capital cities of those countries.
| Key | Value |
|---|---|
| Canada | Ottawa |
| China | Beijing |
| Japan | Tokyo |
| Liechtenstein | Vaduz |
| Malaysia | Kuala Lumpur |
| Nepal | Kathmandu |
| New Zealand | Wellington |
| United Arab Emirates | Abu Dhabi |
| United Kingdom | London |
| United States | Washington D.C. |
The set of keys in a dictionary must be unique (if we try to create a new key:value pair in a dictionary where that key already exists, the key is mapped to the new value and the old value is forgotten). In Python, the keys can be any immutable object type, including strings, numbers and tuples, but not lists (as lists are mutable sequences). Where tuples are used as keys, they can only contain strings, numbers or tuples as elements i.e. no mutable object can be used as an element in a tuple key.
2.1. Defining a Dictionary
A dictionary in Python is created using curly braces {}. Dictionaries may be instantiated with their initial key:value pairs (by defining a comma-separated list of key:value pairs within the curly braces, where the keys and values in a single pair are separated by the colon : character) or as an empty dictionary as follows:
# Create an empty dictionary
my_empty_dict = {}
print(my_empty_dict)
# Create a dictionary mapping countries (keys) to their population size in millions (value)
country_population_dict = {
"China": 1394,
"India": 1326,
"Japan": 126,
"United Kingdom": 66,
"United States": 330
}
print(country_population_dict)
We can also use the dict() Python constructor function to create a dictionary given a sequence of key-value pairs as follows:
# Create a dictionary using the dict() function and a list of tuples
country_population_dict = dict([
("China", 1394),
("India", 1326),
("Japan", 126),
("United Kingdom", 66),
("United States", 330)
])
print(country_population_dict)
2.2. Accessing Dictionary Items
In list and tuple collection data structures, elements are accessed by their index numbers (i.e. indexing). However dictionaries are indexed by their keys, which make dictionaries optimal data structures for fast and efficient lookup operations. To access a value in a dictionary by its key, we simply use square brackets [] containing the key, or the dictionary get() method given the key, as follows:
# Access a dictionary value item by its key using square brackets
japan_population_m = country_population_dict["Japan"]
print(f'The population of Japan is {japan_population_m}m')
# Access a dictionary value item by its key using the get() method
print(f'The population of China is {country_population_dict.get("China")}m')
If we attempt to lookup a value by a non-existent key using square brackets [], Python will return a KeyError exception. However if we attempt to lookup a value by a non-existent key using the get() dictionary method, then None will be returned, as follows:
# Perform a lookup using a non-existent key using square brackets
brazil_population_m = country_population_dict["Brazil"]
print(f'The population of Brazil is {brazil_population_m}m')
# Perform a lookup using a non-existent key using the get() method
print(f'The population of Brazil is {country_population_dict.get("Brazil")}m')
2.3. Modifying Dictionary Items
Values for existing keys can be updated using square brackets [] containing the relevant key, and the assignment = operator. Python will map the key to the new value, and the old value will be forgotten, as follows:
# Create a dictionary of GDP rankings by country
gdp_rankings_dict = {
"China": 2,
"India": 8,
"Japan": 3,
"United Kingdom": 5,
"United States": 1
}
print(gdp_rankings_dict)
# Modify the ranking of an existing country
gdp_rankings_dict["India"] = 7
print(gdp_rankings_dict)
2.4. Adding Dictionary Items
Key:value pairs can be added to an existing dictionary simply by defining a new index key within square brackets [] along with the assignment = operator, as follows:
# Add a country to the population dictionary
print(country_population_dict)
country_population_dict["South Korea"] = 52
print(country_population_dict)
As of Python 3.7, dictionaries will maintain the insertion order of key:value pairs. Note that in the example above, the key:value pair for South Korea is the last key:value pair in the collection.
2.5. Removing Dictionary Items
Specific key:value pairs can be removed from an existing dictionary using the del keyword applied to the index key that requires deletion provided in square brackets [], as follows:
# Remove a key:value pair from the country population dictionary usign the del keyword
print(country_population_dict)
del country_population_dict["Japan"]
print(country_population_dict)
We can also use the pop() method for dictionaries to remove a key:value pair given the key. As of Python 3.7, the popitem() method for dictionaries will remove the last inserted item. Before Python 3.7, the popitem() method would have removed a randon key:value pair instead.
# Remove a key:value pair from the country population dictionary usign the pop() method
country_population_dict.pop("United Kingdom")
print(country_population_dict)
# Remove the last inserted key:value pair using the popitem() method
country_population_dict.popitem()
print(country_population_dict)
Finally we can apply the del keyword to the dictionary object without square brackets to delete the dictionary completely, as follows:
# Delete the GDP rankings dictionary
print(gdp_rankings_dict)
del gdp_rankings_dict
print(gdp_rankings_dict)
2.6. Iterating Dictionaries
It is common to use a for loop to iterate over the key:value pairs in a given dictionary. By default, a for loop will iterate over the keys in a given dictionary, as follows:
# Use a for loop to iterate through the keys in a given dictionary, printing the keys
for key in country_population_dict:
print(key)
print()
# Use a for loop to iterate through the keys in a given dictionary, printing the values
for key in country_population_dict:
print(country_population_dict[key])
We use the values() dictionary method to iterate over the values in a given dictionary. And finally, we can use the items() dictionary method to simultaneously iterate over both keys and values in a given dictionary, as follows:
# Use the values() method to iterate over the values of a dictionary
for v in country_population_dict.values():
print(v)
print()
# Use the items() method to iterate over both keys and values of a dictionary
for k, v in country_population_dict.items():
print(f'The population of {k} is {v}m')
2.7. Checking Key Existence
As we saw in section 2.2. Accessing Dictionary Items, if we attempt to lookup a value by a non-existent key using square brackets, Python will return a KeyError exception. And if we attempt to lookup a value by a non-existent key using the get() dictionary method, then None will be returned. In order to test for the existence of a key in an existing dictionary, we can use the in membership operator, as follows:
# Test for the existence of a key in a given dictionary
if "South Korea" in country_population_dict:
print(f'The population of South Korea is {country_population_dict["South Korea"]}m')
else:
print('South Korea does not exist in our dictionary of populations.')
2.8. Dictionary Comprehension
In the Data Aggregates Part 1 module of this course, we studied list comprehension - an elegant and intuitive means to create lists through a one-line statement composed of a valid Python expression, an iterable object and a member object.
Dictionary comprehension is an equivalent means to populate a dictionary with key-value pairs via a one-line statement. Dictionary comprehension is also composed of three components, as follows:
- Key object - an object that will represent the key in the subsequent key-value pairs
- Value expression - any valid Python expression whose return value will represent the value in the subsequent key-value pairs
- Iterable object - any valid object that is iterable, such as a string, a collection, or the evaluation of the
range()function
For example, the following Python statement creates a dictionary containing 10 key-value pairs, where the key is an integer from 1 to 10, the value expression is num * num (i.e. the key squared), and the iterable object is the evaluation of range(1, 11) (which evaluates to and returns the immutable sequence of numbers 1 - 10).
# Create a dictionary of keys (1 - 10) and values (key squared) using dictionary comprehension
squares_dict = {num: num*num for num in range(1, 11)}
print(squares_dict)
Another example is provided below. In this example we have an existing dictionary whose keys are the planets in our solar system, and whose values are the average distance (in km) of those planets from Earth. We then use dictionary comprehension to create a similar dictionary, but this time use a conversion calculation in the value expression to transform the values into average distance in astronomical units (AU) where 1 AU is 149,600,000km. In this example, the key object is the planet key from our original dictionary, the value expression is the calculation to convert from km to AU rounded to 2 decimal places, and the iterable object is the key-value pairs returned by the items() method applied to the original dictionary.
# Create a dictionary of average distance (in km) of planets from the Earth
earth_planets_distance_km_dict = {
"Mercury": 91_691_000,
"Venus": 41_400_000,
"Mars": 78_340_000,
"Jupiter": 628_730_000,
"Saturn": 1_275_000_000,
"Uranus": 2_723_950_000,
"Neptune": 4_351_400_000
}
print(f'Distance between the Earth and the other planets in the Solar System (km):\n{earth_planets_distance_km_dict}\n')
# Convert to AU using dictionary comprehension
km_to_au = 149_600_000
earth_planets_distance_au_dict = { planet: round((km / km_to_au), 2) for (planet, km) in earth_planets_distance_km_dict.items() }
print(f'Distance between the Earth and the other planets in the Solar System (AU):\n{earth_planets_distance_au_dict}')
Finally, and as with list comprehension, we can use conditional statements within our dictionary comprehension statements to both perform filtering, and to change the eventual values. In the following example, we use conditional statements to filter the key:value pairs to only those planets within 100 million km of the Earth.
# Create a dictionary of planets within 100km of the Earth
planetary_neighbour_limit_km = 100_000_000
earth_closest_planets_dict = { k:v for (k, v) in earth_planets_distance_km_dict.items() if v < planetary_neighbour_limit_km }
print(f'Distance between the Earth and our closest planets in the Solar System (km):\n{earth_closest_planets_dict}\n')
And in the following example, we maintain the original unit of distance (km) if the planet is within 100 million km of the Earth, otherwise we transform the distance unit to AU for those planets that exceed 100 million km average distance from the Earth.
# Create a dictionary of average planetary distances from the Earth, using km for the inner planets and AU for the outer planets
km_to_au = 149_600_000
inner_planet_limit_km = 100_000_000
earth_planets_km_au_dict = { k: ( v if v < inner_planet_limit_km else round((v / km_to_au), 2) ) for (k, v) in earth_planets_distance_km_dict.items() }
print(f'Distance between the Earth and the other planets in the Solar System (km for inner planets and AU for outer planets):\n{earth_planets_km_au_dict}')
2.9. Filtering Dictionaries
An elegant means to filter dictionaries is to use dictionary comprehension given a list of keys you wish to filter. In the following example, we filter our dictionary of planets to keep only the inner planets:
# Create a dictionary of average distance (in km) of planets from the Earth
earth_planets_distance_km_dict = {
"Mercury": 91_691_000,
"Venus": 41_400_000,
"Mars": 78_340_000,
"Jupiter": 628_730_000,
"Saturn": 1_275_000_000,
"Uranus": 2_723_950_000,
"Neptune": 4_351_400_000
}
# Filter to keep only the inner planets
inner_planets = ["Mercury", "Venus", "Earth", "Mars"]
earth_inner_planets_distance_km_dict = { key: earth_planets_distance_km_dict[key] for key in set(inner_planets).intersection(earth_planets_distance_km_dict.keys()) }
print(earth_inner_planets_distance_km_dict)
In the example above, the
inner_planetslist of planets to keep contains a planet not in our original dictionary i.e. 'Earth'. In order to avoid an exception being thrown whereby that key cannot be found in our original dictionary, instead of iterating through the keys in that dictionary, we instead find the common keys between the uniquesetof keys from theinner_planetslist and the keys inearth_planets_distance_km_dictusing theintersection()method.
2.10. Copying Dictionaries
In the Data Aggregates Part 1 module of this course, we studied how we can make shallow and deep copies of lists. The copying of lists can be generalised to mutable collections, or collections that contain mutable elements, such as dictionaries. When we create a shallow copy of such a collection, we create a new collection but whose elements are references to those objects found in the original. When we create a deep copy of a collection, we create a new collection and recursively create copies of the elements found in the original i.e. cloning or a true copy. In the following example, we create a shallow copy of a dictionary and then make changes to the original to see if this change is reflected in the copy.
# Create a dictionary of average distance (in km) of planets from the Earth
earth_planets_distance_km_dict = {
"Mercury": 91_691_000,
"Venus": 41_400_000,
"Mars": 78_340_000,
"Jupiter": 628_730_000,
"Saturn": 1_275_000_000,
"Uranus": 2_723_950_000,
"Neptune": 4_351_400_000
}
print(earth_planets_distance_km_dict)
# Create a shallow copy of this dictionary
shallow_copy_dict = earth_planets_distance_km_dict
shallow_copy_dict["Earth"] = 0
# Modify the original dictionary and observe changes to the shallow copy
earth_planets_distance_km_dict["Neptune"] = 29.09
print(earth_planets_distance_km_dict)
print(shallow_copy_dict)
And in the following example, we instead make a deep copy of a dictionary via the copy module and associated deepcopy() function, and then make similar changes to the original to confirm that these changes are not reflected in the clone.
import copy
# Create a dictionary of average distance (in km) of planets from the Earth
earth_planets_distance_km_dict = {
"Mercury": 91_691_000,
"Venus": 41_400_000,
"Mars": 78_340_000,
"Jupiter": 628_730_000,
"Saturn": 1_275_000_000,
"Uranus": 2_723_950_000,
"Neptune": 4_351_400_000
}
print(earth_planets_distance_km_dict)
# Create a deep copy of this dictionary
deep_copy_dict = copy.deepcopy(earth_planets_distance_km_dict)
deep_copy_dict["Earth"] = 0
# Modify the original dictionary and observe no changes to the deep copy
earth_planets_distance_km_dict["Neptune"] = 29.09
print(earth_planets_distance_km_dict)
print(deep_copy_dict)
2.11. Nested Dictionaries
Similar to lists and tuples, we can create nested dictionaries or multi-dimensional dictionaries (i.e. dictionaries within dictionaries). A simple way to create nested dictionaries is to explicitly define all child dictionaries as follows:
import pprint
# Create a nested dictionary
nested_multiplication_table_2d_dict = {
1: {
1:1, 2:2, 3:3, 4:4, 5:5
},
2: {
1:2, 2:4, 3:6, 4:8, 5:10
},
3: {
1:3, 2:6, 3:9, 4:12, 5:15
},
4: {
1:4, 2:8, 3:12, 4:16, 5:20
},
5: {
1:5, 2:10, 3:15, 4:20, 5:25
}
}
pprint.pprint(nested_multiplication_table_2d_dict)
However a better and more elegant means to create a nested dictionary is to use dictionary comprehension. In the following example, we create the same nested dictionary as above but using dictionary comprehension.
# Create the same nested dictionary using dictionary comprehension
nested_multiplication_table_2d_dict = { key1: {key2: key1 * key2 for key2 in range(1, 6)} for key1 in range(1, 6) }
pprint.pprint(nested_multiplication_table_2d_dict)
2.12. Dictionaries from Tuples
We can elegantly create a dictionary given a list of tuples using dictionary comprehension. In the following example, we have a list of tuples where the first element in each tuple represents a country and the second element is its area size in km2. From this, we use dictionary comprehension with the indexing of the tuples to create an equivalent dictionary of the same countries to their respective area size, as follows:
# Create a list of tuples containing countries and their size in km^2
country_area_tuples = [("Russia", 17_098_242), ("Canada", 9_984_670), ("United States", 9_857_348), ("China", 9_596_961)]
print(country_area_tuples)
# Convert this list of tuples to an equivalent dictionary
country_area_dict = { key[0]: key[1] for key in country_area_tuples}
pprint.pprint(country_area_dict)
2.13. Sparse Matrix
In the Data Aggregates Part 1 module of this course, we studied how a matrix can be represented as a list of lists i.e. a two-dimensional array. In Linear Algebra, a Sparse Matrix is a matrix where most of its elements are zero (the opposite of a sparse matrix, where most of its elements are non-zero, is commonly referred to as a dense matrix). An example of a sparse matrix is provided in the following image:
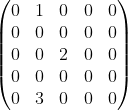
Whilst lists can be used to represent a sparse matrix (and any other type of matrix), dictionaries too may be an ideal collection with which to represent a sparse matrix. In the following example, we represent the sparse matrix provided in the image above via a dictionary of tuples keys containing elements corresponding to the row and column numbers respectively. This dictionary will only store the non-zero elements of our sparse matrix, as follows:
# Create a sparse matrix with a dictionary of tuple keys
sparse_matrix_dict = {(0, 1): 1, (2, 2): 2, (4, 1): 3}
print(f'The value of the element at row 0 and column 1 is {sparse_matrix_dict.get((0, 1), 0)}')
print(f'The value of the element at row 0 and column 3 is {sparse_matrix_dict.get((0, 3), 0)}')
print(f'The value of the element at row 2 and column 1 is {sparse_matrix_dict.get((2, 1), 0)}')
print(f'The value of the element at row 2 and column 2 is {sparse_matrix_dict.get((2, 2), 0)}')
print(f'The value of the element at row 4 and column 1 is {sparse_matrix_dict.get((4, 1), 0)}')
In the example above, we use the
get()method to return the value of the element at the given row and column number (key) in our sparse matrix. Recall that theget()method will returnNoneif the given key does not exist. In our case, we provide an additional parameter to theget()method which represents the default value if the key is not found in the dictionary i.e. 0.
2.14. Common Dictionary Methods
The dictionary collection in Python provides the following methods on the dictionary object which can be used to access, insert, modify and delete dictionary key:value pairs.
dict.clear()- removes all key:value pairs from the dictionarydict.copy()- returns a copy of the dictionarydict.fromkeys(keys, value)- returns a dictionary using the given iterable of keys and the optional given valuedict.get(key, default)- returns the value of the given key. If the key is not found, then the given default value is returned.dict.items()- returns a list of tuples for each key:value pairdict.keys()- returns a list of dictionary keysdict.pop(key, default)- removes the key:value pair with the given key and returns it value. If the key is not found, then the given default value is returned.dict.popitem()- as of Python 3.7, this removes the last key:value pair that was inserted. Before Python 3.7, this removes a random key:value pair.dict.setdefault(key, value)- returns the value of the given key. If the key is nout found, the this will create a new key:value pair with the given key and given value.dict.update(iterable)- updates the dictionary with the given key:value pairs. If the key is already exists in the dictionary, then the value is updated with the given value. If the key does not exist in the dictionry, then a new key:value pair is added to the dictionary.dict.values()- returns a list of dictionary values
import pprint
# Create a dictionary
earth_planets_distance_km_dict = {
"Mercury": 91_691_000,
"Venus": 41_400_000,
"Mars": 78_340_000,
"Jupiter": 628_730_000,
"Saturn": 1_275_000_000,
"Uranus": 2_723_950_000,
"Neptune": 4_351_400_000
}
pprint.pprint(earth_planets_distance_km_dict)
print()
# dict.clear()
nested_multiplication_table_2d_dict = { key1: {key2: key1 * key2 for key2 in range(1, 6)} for key1 in range(1, 6) }
pprint.pprint(nested_multiplication_table_2d_dict)
nested_multiplication_table_2d_dict.clear()
pprint.pprint(nested_multiplication_table_2d_dict)
print()
# dict.copy()
copy_dict = earth_planets_distance_km_dict.copy()
pprint.pprint(copy_dict)
print()
# dict.fromkeys(keys, value)
keys = [2, 3, 5, 7, 11]
prime_dict = dict.fromkeys(keys)
pprint.pprint(prime_dict)
v = "prime"
labelled_prime_dict = dict.fromkeys(keys, v)
pprint.pprint(labelled_prime_dict)
print()
# dict.get(key, default)
print(earth_planets_distance_km_dict.get("Venus"))
print(earth_planets_distance_km_dict.get("Earth"))
print(earth_planets_distance_km_dict.get("Earth", 0))
print()
# dict.items()
print(earth_planets_distance_km_dict.items())
print()
# dict.keys()
print(earth_planets_distance_km_dict.keys())
print()
# dict.pop(key, default)
print(earth_planets_distance_km_dict.pop("Neptune"))
print(earth_planets_distance_km_dict.pop("Earth", 0))
print()
# dict.popitem()
earth_planets_distance_km_dict["Earth"] = 0
print(earth_planets_distance_km_dict)
earth_planets_distance_km_dict.popitem()
print(earth_planets_distance_km_dict)
print()
# dict.setdefault(key, value)
pluto_average_distance_km = earth_planets_distance_km_dict.setdefault("Pluto", 4_970_600_000)
print(pluto_average_distance_km)
print(earth_planets_distance_km_dict)
print()
# dict.update(iterable)
dict_updates = {"Sun": 151_460_000, "Asteroid Belt": 390_400_000}
earth_planets_distance_km_dict.update(dict_updates)
pprint.pprint(earth_planets_distance_km_dict)
print()
# dict.values()
print(earth_planets_distance_km_dict.values())
2.15. Common Dictionary Functions
Python provides the following but non-exhaustive list of functions that may be applied to dictionaries:
len(dict)- returns the number of key:value pairs in the given dictionary
# len()
pprint.pprint(earth_planets_distance_km_dict)
print(len(earth_planets_distance_km_dict))
Summary
In this module we have covered two further common collection data structures in Python, namely tuples and dictionaries. We now have the ability to create tuples, and we understand the fundamental similarities and differences between lists and tuples, and subsequent typical use-cases. We also have an understanding of dictionary collections and associated operations and common methods. We can create dictionaries from iterables using dictionary comprehension, and we can represent sparse matrices using dictionaries.
Homework
Dictionary Comprehension - Inverted Mappings
Write a Python program that uses dictionary comprehension to invert any given dictionary (i.e. keys become values, and values become keys). For example your Python program should return the following inverted dictionary given the dictionary {1: 'a', 2: 'b', 3: 'c'}:{'a':1, 'b':2, 'c': 3}Letter Frequency
Write a Python program that, given a word, will return a dictionary where the keys are the unique letters found in that word, and the corresponding values are the frequency of that letter in the word. For example your Python program should return the following dictionary given the word 'abracadabra':{'a': 5, 'b': 2, 'r': 2, 'c': 1, 'd': 1}Dictionary Comprehension - Word Frequency
Write a Python program that, given a string of words, uses dictionary comprehension to return a dictionary where the keys are the unique words found in that string, and the corresponding values are the frequency of that word in the string. For example your Python program should return the following dictionary given the string 'How much wood would a woodchuck chuck if a woodchuck could chuck wood? He would chuck, he would, as much as he could, and chuck as much wood as a woodchuck would if a woodchuck could chuck wood':
{'He': 1,
'How': 1,
'a': 4,
'and': 1,
'as': 4,
'chuck': 5,
'could': 3,
'he': 2,
'if': 2,
'much': 3,
'wood': 4,
'woodchuck': 4,
'would': 4}
What's Next
In the next module, we will formally introduce functions, generator functions and lambda functions in Python, starting with formal definitions before exploring their structure and core components, including parameters, arguments, name scope, and important keywords such as return, yield and None.
Curriculum